
Our team met MIRA Network during the OVHcloud Startup Program Fast Forward Blockchain and Web3 Accelerator. They requested to upgrade their project to a Seed A grade with a tailored, high-available blockchain infrastructure by Senior DevOps.

MIRA Network is building a Web3 crowdfunding and Real-World Asset (RWA) tokenisation ecosystem operating at production scale. When your platform handles millions of users and processes 19 million queries weekly, infrastructure isn't just a cost center—it is the foundation of user trust.
MIRA faced an infrastructure challenge: an expensive, manually configured setup that lacked visibility and drained the runway without delivering the required reliability.
The project was led by a dedicated Lead Infrastructure Architect and a Senior DevOps Engineer, who translated MIRA’s business requirements into a resilient technical blueprint.
This success was amplified by our close cooperation with the OVHcloud team, whose direct support and technical offers ensured a seamless transition to their ecosystem.
The initial infrastructure was a "black box" of manual configurations. Without Infrastructure as Code (IaC), every change was a risk, and troubleshooting felt like guesswork. The primary pain points included:
MIRA needed a partner to migrate to a more cost-effective, high-performance environment while implementing modern DevOps standards from the ground up.
Another limitation of the project was the timeframes—two engineers had less than two months to design and implement the solution.
Dysnix engineered, planned, and conducted a prompt transition to OVHcloud, leveraging high-performance cloud and managed Kubernetes services. The strategy focused on "right-sizing," "automation-first," and visibility principles.
Database footprint reduced via rightsizing and instance type changes. Although infrastructure was created via UI, early-stage autoscaling tuned toward overprovisioning, we decided to fix the core problem of infrastructure design first and deal with scalability issues later. And we installed monitoring, alerting, and logs from day zero of the new OVHcloud-based infrastructure.
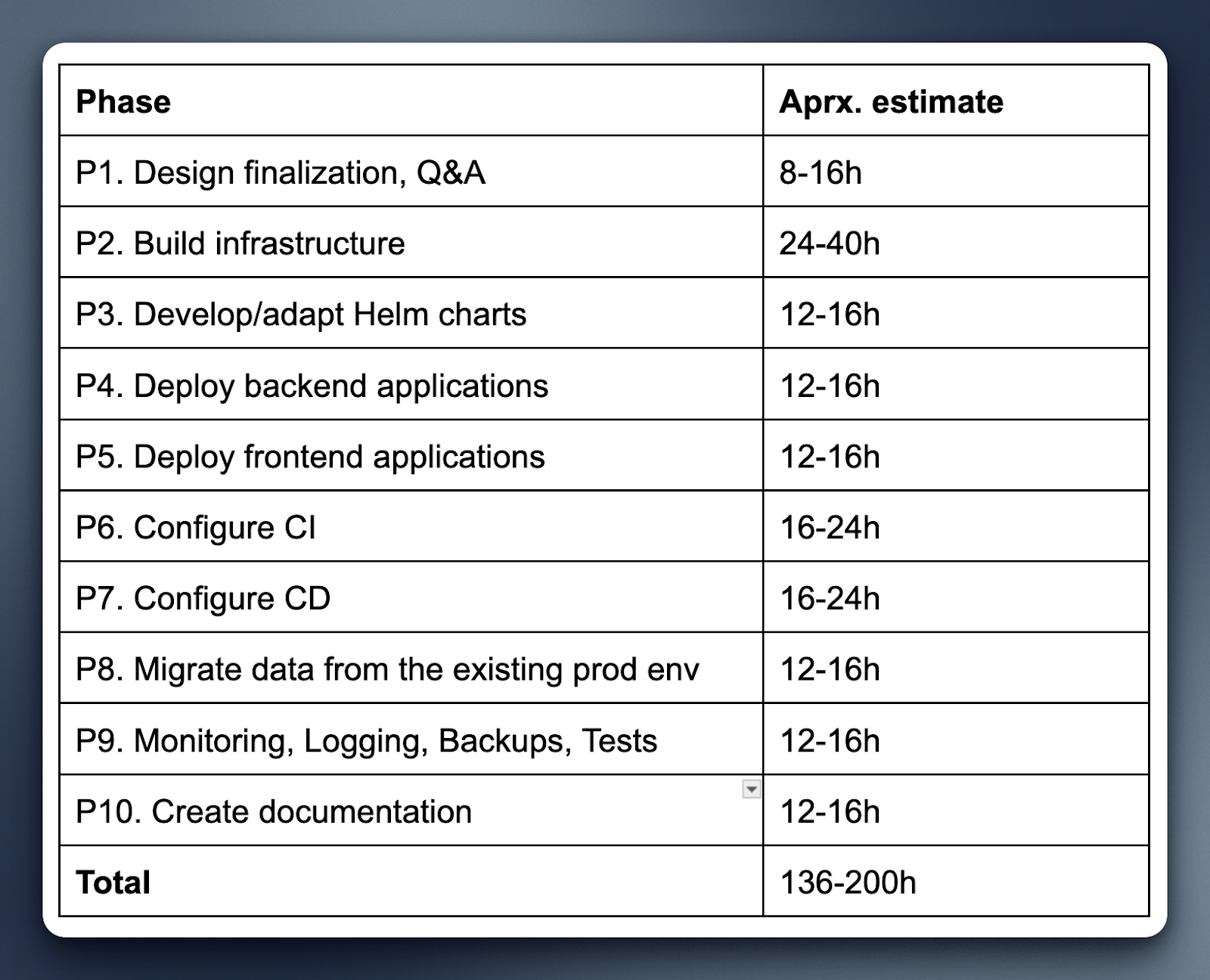
We moved the core backend and data layers into a streamlined, two-zone high-availability setup in the OVHcloud Germany (Limburg) region that worked best for the client. We chose optimal instance types and sizes based on traffic needs. The whole architecture schema looked as follows:
High-level overview:
The MIRA backend application was containerized and deployed into the managed Kubernetes cluster with zero manual steps.
The frontend assets were migrated from AWS S3 and CloudFront to OVHcloud's object storage and CDN, reducing latency for end users globally. We've configured CI/CD pipelines for frontend, ensuring new versions are seamlessly deployed to S3.
Static assets were cached aggressively at the edge, while HTML was served with short TTLs to allow rapid updates. This unified deployment model eliminated the operational friction of managing separate frontend and backend release cycles.
The previous setup relied on manual deployments and ad-hoc scripts. We implemented a GitHub-based CI/CD pipeline using industry-standard tools that automated every step from code commit to production release. The pipeline included:
This shift from manual to automated deployment reduced deployment time from hours to minutes and eliminated human error as a source of outages.
The previous AWS setup had no centralized observability. When issues occurred, the team was reactive—discovering problems only after users reported them. We implemented a three-layer monitoring stack to transform MIRA into a self-healing, self-aware system.
Prometheus scrapes metrics from every Kubernetes node, pod, and application endpoint every 15 seconds. This captures CPU, memory, disk I/O, network throughput, and custom application metrics, such as query latency and blockchain transaction confirmation times.
Grafana stack (Loki, Alloy, Grafana) dashboards provide real-time visualization of system health. The team now sees query patterns, database connection pools, and pod restart rates at a glance. Custom dashboards track MIRA-specific KPIs: user login rates, tokenization transaction volume, and AI verification accuracy.
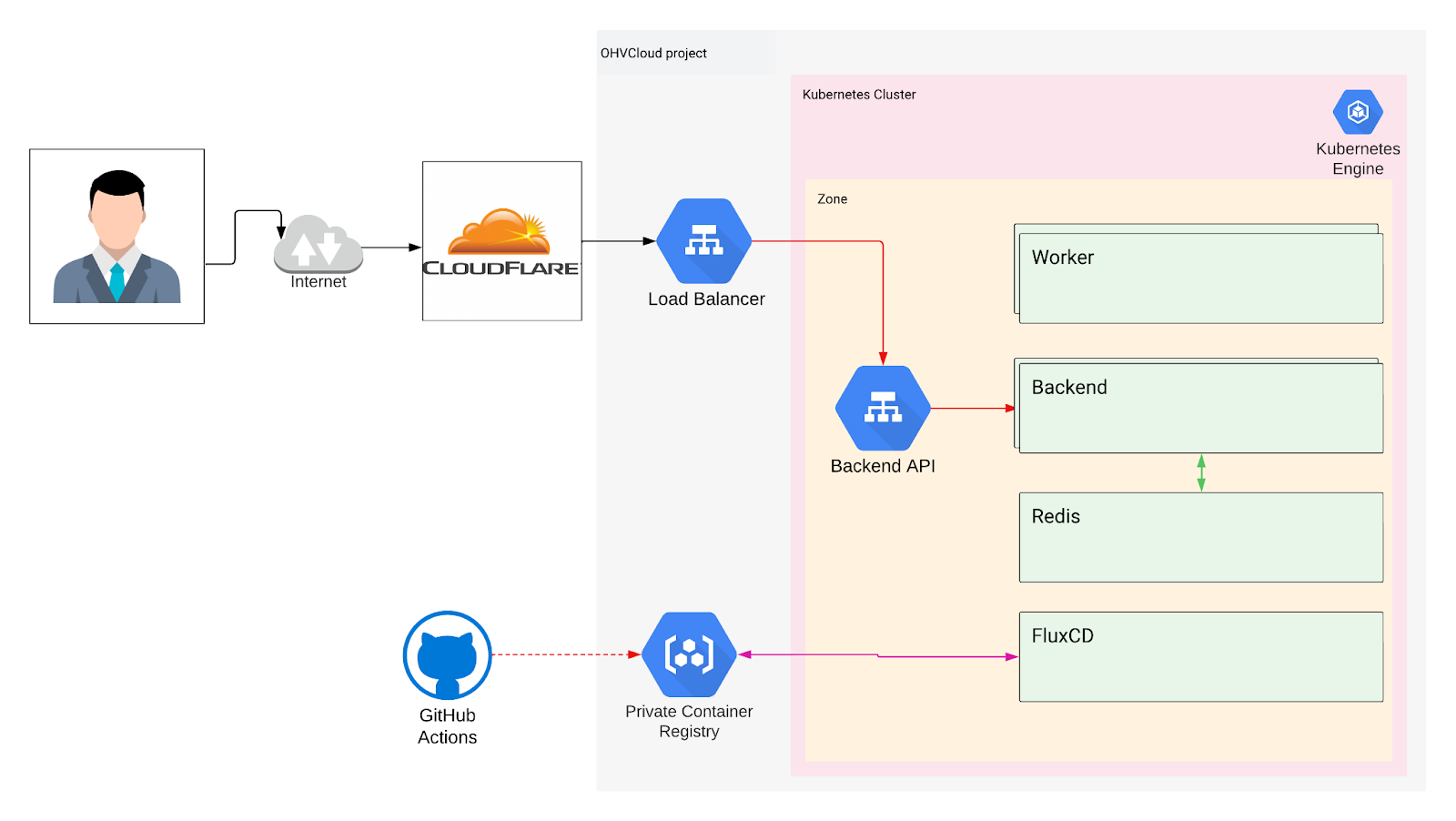
Alert rules are defined in code and version-controlled alongside infrastructure. Thresholds trigger automated responses, and an alert fires to the on-call engineer.
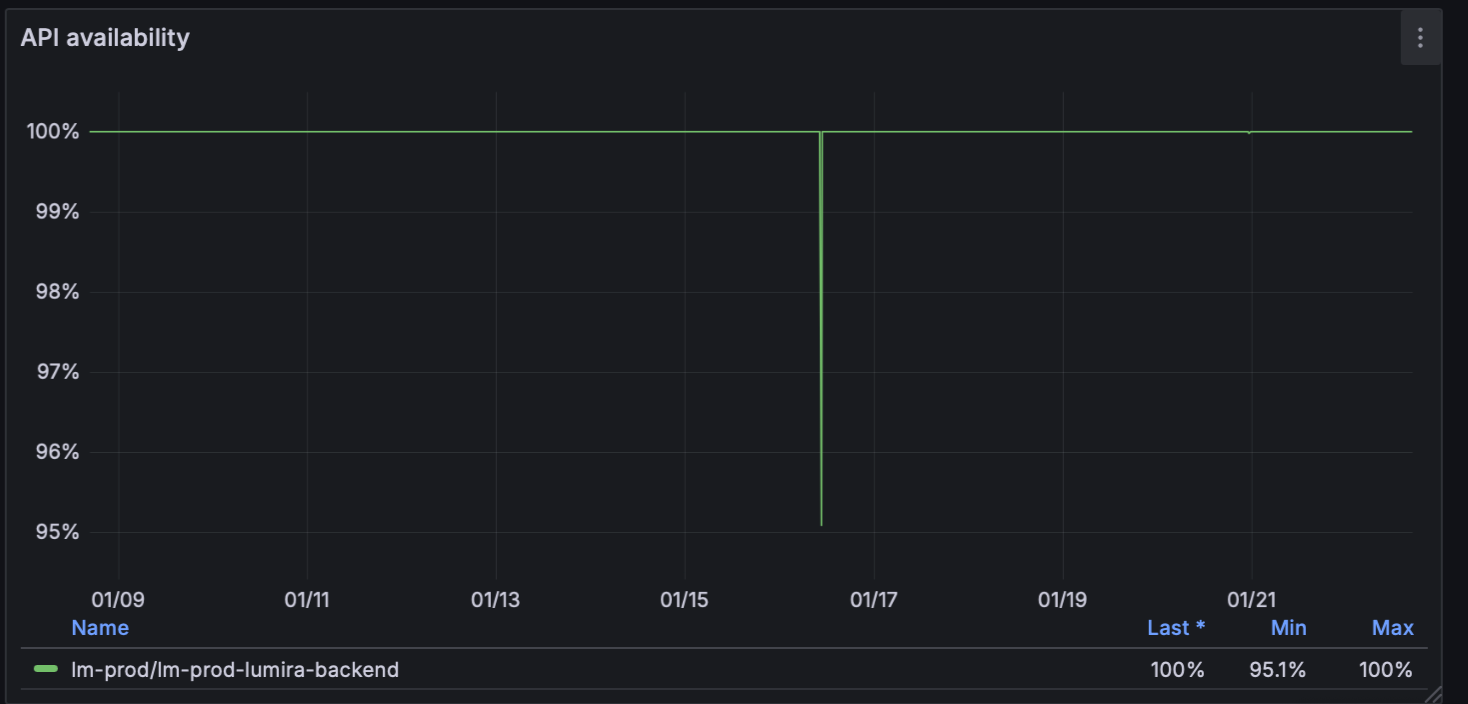
The result is a system that no longer surprises. MIRA's engineering team now spends time optimizing, not firefighting.
To ensure MIRA’s four million users experienced no disruption, we utilized a blue/green deployment strategy. We built the entire target environment in parallel using Terraform and Helm. Data replication was established between AWS and OVHcloud to keep the state in sync until the final moment of transition.
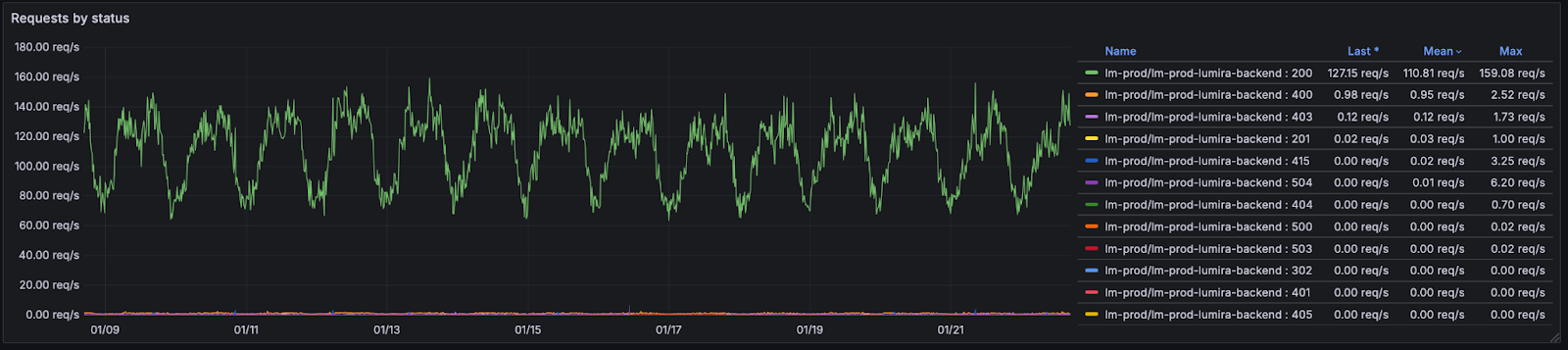
The actual cutover was completed in under 10 minutes. We maintained the AWS environment as a "warm standby" for seven days to provide a guaranteed rollback path, though it was never needed. The result was a clean break from legacy debt into a documented, version-controlled infrastructure.
By moving to a managed Kubernetes environment on OVHcloud and rightsizing the database clusters, MIRA Network achieved:
The migration represents the first phase of MIRA’s infrastructure maturity. As the ecosystem continues to scale in line with its 2026 roadmap as a Web3 crowdfunding and RWA tokenisation ecosystem, the following enhancements are planned:
MIRA Network now possesses the technical foundation to scale from millions to tens of millions of users without the fear of infrastructure collapse or runaway costs.

Build faster with private RPC by Dysnix
Dedicated endpoints, gRPC, and raw streams for trading, AI agents, and dApps.
Test for free











.jpg)





