
For the last year, MEV revenue on Solana reached $720 million, surpassing priority fees as the single largest source of real economic value on the network (Helius Ecosystem Report H1 2025). By mid-2026, that figure is tracking higher. The Jito Block Engine alone generated $4.7 million in fees in Q3 2025—a single quarter.
The standard narrative frames MEV as a strategy problem. Find the arbitrage. Detect the liquidation. Calculate the sandwich. But the searchers who captured the majority of that $720 million were not running more sophisticated strategies than their competitors. In most cases, they were running better infrastructure. This article breaks down every layer of that infrastructure—and why each one directly determines whether a MEV setup generates profit or generates failed bundles.
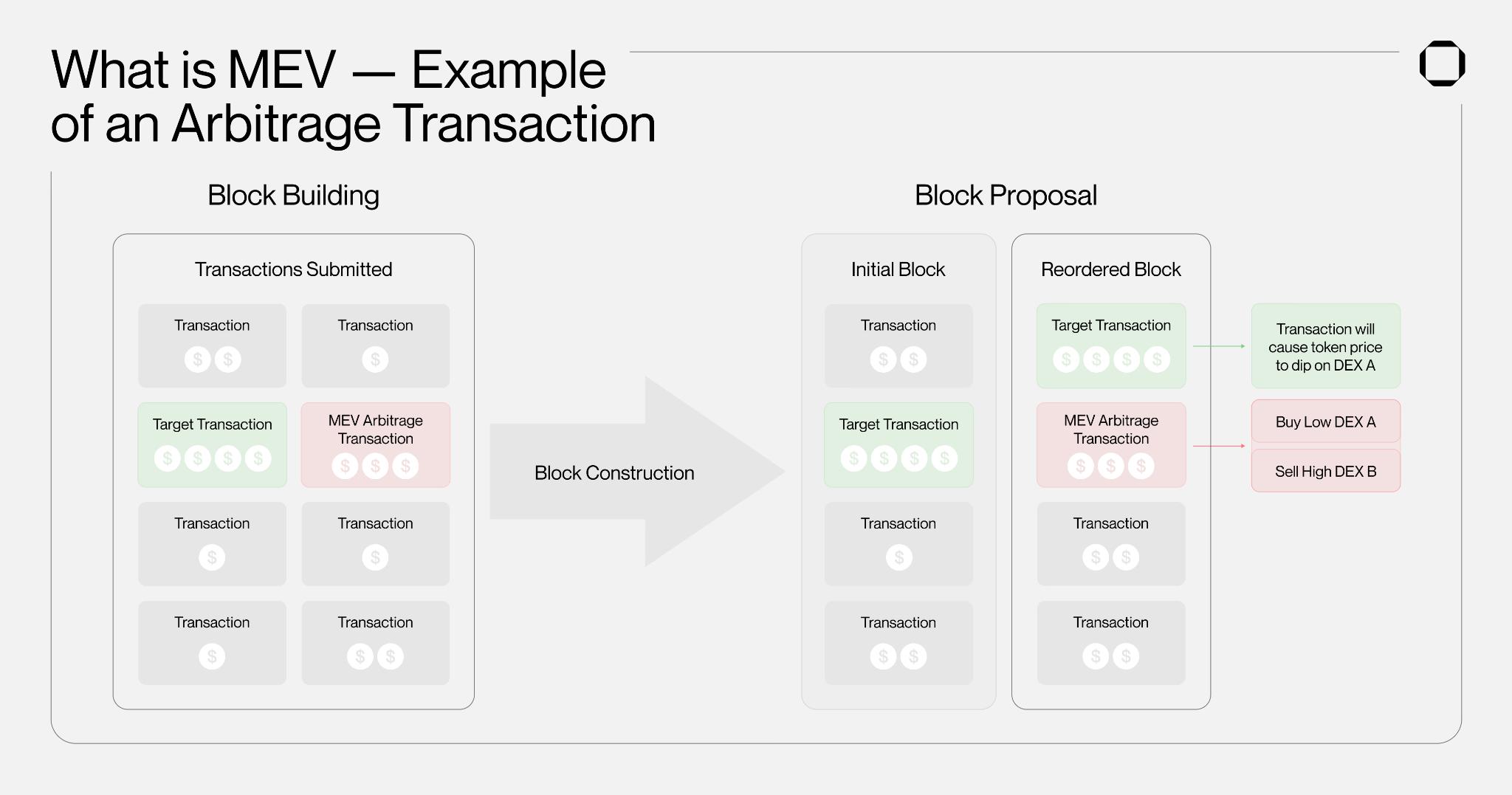
Understanding why infrastructure dominates MEV outcomes on Solana starts with the slot architecture. The network produces a block every 400 milliseconds. The validator responsible for that block—the slot leader—rotates every four slots, roughly every 1.6 seconds, cycling through hundreds of validators distributed globally.
On Ethereum, a 12-second block time gives searchers a generous window to observe pending transactions in the public mempool, simulate outcomes, and submit bids. On Solana, that window is measured in single-digit milliseconds from signal detection to bundle submission. There is no public mempool—private relay infrastructure is the only submission path. And the slot leader's identity and location changes before most strategies complete a single evaluation cycle.
The practical consequence of Solana's architecture: winning MEV requires being physically closer to the current leader, receiving state updates before competitors do, and delivering bundles through paths that the leader's validator client prioritizes. Code quality sets the ceiling. Infrastructure determines how close you get to it.
Every serious MEV operation on Solana runs on dedicated bare-metal hardware. This is not a cost optimization decision—it's a physics decision. On a shared virtual machine, CPU cycles and memory bandwidth compete with other tenants on the same physical host. Under Solana's sustained throughput, that contention produces latency spikes at exactly the moments when precision matters most.
The validator minimum specification calls for 12 cores at 2.8 GHz. Competitive MEV operations deploy significantly beyond this. Community benchmarks from mid-2026 consistently show AMD EPYC processors leading for MEV-optimized setups—specifically for their high single-thread clock speed, large L3 cache, and hardware support for SHA and AVX2 extensions used in transaction verification.
The failure mode of inadequate hardware is not obvious latency—it's tail latency. A cloud VM may show 40ms average response time under normal conditions and 800ms p99 during a high-traffic event. The MEV bot misses the contested slot and the loss never appears in a latency dashboard.
Network packets travel at approximately two-thirds the speed of light through fiber. A server 150ms round-trip from the nearest validator cluster submits bundles into the middle of the current slot—or misses it and waits for the next. No software optimization eliminates this constraint.
The Solana validator set is globally distributed but concentrated in specific data center clusters. As of mid-2026, the highest density of high-stake validators operates in US East Coast facilities—primarily Ashburn, VA and New York metro. Secondary clusters run in Frankfurt and Amsterdam in Western Europe, with growing presence in Tokyo and Seoul. The current slot leader changes every four slots, meaning optimal geographic positioning shifts continuously across the leader schedule.
The highest-performing MEV setups colocate the trading bot, the RPC node, and the validator on the same physical LAN segment. This configuration eliminates external network hops between three critical components: the state reader, the bundle submitter, and the validator handling inclusion. Dysnix internal benchmarks show 5–10x latency reduction between a colocated setup and a remote cloud instance for the same submission path.
Three specific improvements come from same-datacenter colocation:
Dysnix colocates MEV client infrastructure in Frankfurt, London, and New York East—specifically in OVH, Equinix, Latitude, and TeraSwitch facilities selected for their validator peering density and bloXroute relay proximity. Multi-region deployment with dynamic leader-aware routing switches the active submission path to the geographically nearest node before each slot, rather than after the leader change has already occurred.
Most developers start with WebSocket subscriptions for on-chain data. The API is simple, the documentation is thorough, and it works acceptably for monitoring and lower-frequency strategies. For MEV, it introduces a structural disadvantage—WebSocket delivers JSON-encoded data over HTTP/1.1, routed through the standard RPC processing layer after the network has already propagated the relevant state.
Two data streaming options eliminate this delay:
Yellowstone gRPC—also known as Dragon's Mouth—is the open-source implementation of Solana's Geyser plugin interface developed by Triton One. It delivers account updates, transaction notifications, and slot changes via Protocol Buffers over HTTP/2, tapping data directly from validator memory before it traverses the standard RPC serialization pipeline.
Server-side filtering is Yellowstone's second major advantage for MEV operations. A liquidation monitor tracking undercollateralized positions on a lending protocol subscribes only to the relevant account set—not to every state change on the network. This eliminates bandwidth overhead and CPU cycles spent discarding irrelevant data, which compounds into meaningful latency reduction during high-activity periods.
Yellowstone subscription capabilities relevant to MEV:
Where Yellowstone delivers structured state data after transactions confirm, Jito ShredStream delivers raw block fragments as the slot leader produces them—before full block propagation begins. Subscribers receive shreds 50–200ms ahead of standard Turbine gossip, giving MEV bots visibility into incoming transaction flows while they're still in transit.

For sub-slot arbitrage strategies that depend on detecting large incoming swaps and responding in the same block, ShredStream provides the detection window. Without it, the bot reacts to confirmed state—which is already one step behind competitors who acted on pending state.
Transaction construction is the final step before the outcome is determined by submission infrastructure. Three paths carry MEV transactions to validators, and the best setups use all three simultaneously.
With approximately 92% of validators by stake weight running the Jito-Solana client, the Jito block engine is the primary MEV submission infrastructure on the network. Bundles submitted through Jito can contain up to five transactions that execute atomically in sequence, with an attached SOL tip that determines inclusion priority among competing bundles. Higher tips displace lower tips for the same block position—making tip calibration a live competitive variable rather than a configuration setting.
Two properties distinguish Jito bundles from standard transaction submission: guaranteed execution order within the bundle eliminates the multi-step execution risk that standard sendTransaction carries, and removal from the public submission pool eliminates exposure to sandwich attacks that operate on observable pending transactions.
bloXroute's Blockchain Distribution Network routes transactions through a purpose-built global relay mesh rather than Solana's standard gossip network. Its geographic diversity covers leader-schedule edge cases where the active validator sits in a region with weaker direct Jito relay coverage.
%201.jpg)
In October 2025, bloXroute introduced real-time leader scoring—a system that evaluates current and upcoming slot leaders for malicious ordering risk, identifies validators with elevated sandwich attack correlation, and dynamically adjusts submission timing. Bundles destined for high-risk leaders can be delayed or rerouted automatically, while trusted validators receive accelerated submission. For MEV strategies sensitive to execution ordering, this mechanism reduces adversarial inclusion risk without requiring manual monitoring of the validator set.
Solana's Stake-Weighted Quality of Service mechanism allocates approximately 80% of each validator's TPU bandwidth to transactions arriving through staked validator connections. The remaining 20% serves all other traffic—including public RPC submissions. During network saturation, the public pool fills and transactions drop. Transactions forwarded through staked connections receive priority processing regardless of congestion level.
Dysnix operates staked validator relationships that allow client transactions to enter the protected bandwidth allocation. For MEV strategies that fire during high-traffic events—exactly when public paths saturate—SWQoS access is the difference between consistent inclusion and systematic rate-limiting.
A MEV setup that performs at 95th percentile during normal conditions but degrades during volatile events captures less value than a setup that performs at 85th percentile consistently. Operational reliability is not a secondary concern—it's a direct profitability variable.
Five monitoring and operational requirements determine whether a MEV setup maintains performance under pressure:
Dysnix runs proprietary benchmark probes every 15 minutes against live network conditions. When leader schedule changes shift optimal routing configuration, the system adapts before the next epoch rather than after client-reported degradation.
Every layer described in this article can be assembled independently. Colocation space is rentable. Bare-metal EPYC servers are provisionable. Yellowstone gRPC is open source. Jito and bloXroute have public documentation. Teams build this themselves. The typical timeline from initial provisioning to a competitive production setup is three to six months, followed by ongoing operational work that scales with the number of active strategies.
The operational cost is the less visible number. Monitoring infrastructure requires 24/7 attention. Validator client updates arrive regularly and some are critical—missing one can leave a node running on a version the rest of the network has already passed. Leader schedule changes, relay policy updates, and network upgrades each require configuration responses. For a small team focused on strategy development, this operational overhead competes directly with the work that generates alpha.
Managed MEV infrastructure exists because the infrastructure itself is not the edge. The edge is in the strategy that runs on it. Dysnix provisions and maintains the full stack described in this article—bare-metal EPYC hardware, colocation in validator-dense facilities, Jito ShredStream and bloXroute integration, Yellowstone gRPC, SWQoS-enabled submission, and 24/7 monitoring with sub-50ms automated failover. Over 100 active MEV configurations run on Dysnix infrastructure. Clients report consistent 40% latency reductions from previous setups, with engineering time redirected from infrastructure debugging to strategy development.
Serious about MEV on Solana?
Dysnix runs the complete MEV infrastructure stack for trading teams—bare-metal EPYC colocation, Jito ShredStream, Yellowstone gRPC, bloXroute integration, SWQoS submission, and 24/7 monitoring with sub-50ms automated failover.
Speak with the Dysnix team → dysnix.com

Build faster with private RPC by Dysnix
Dedicated endpoints, gRPC, and raw streams for trading, AI agents, and dApps.
Test for free










.jpg)





