
Everyone loves talking about the “intelligence” part of a Solana AI agent. The LLM. The clever prompts. The strategy logic that looks great in a demo. Infrastructure gets treated like electricity—flip the switch, assume it works, move on.
That assumption is where things start breaking. What shows up in production isn’t some exotic edge case. It’s three boring, repeatable failure modes that quietly eat your P&L.
None of this is surprising. This is what commodity infrastructure does under pressure.
The part people miss is the consequence: the difference between a shared public RPC and a dedicated, colocated node isn’t academic. It shows up directly in execution quality, fill rate, and missed opportunities. In other words, your P&L.
If you come from Ethereum, you think in seconds. Solana doesn’t give you that luxury. Time is sliced into 400ms slots, and you either hit the slot or you don’t.
“Low latency” here isn’t a vague goal. It has three concrete properties.
Now here’s the trap: averages look fine. On a quiet day, a shared RPC endpoint and a dedicated bare-metal node produce similar latency graphs. If you stop there, everything looks healthy.
Then the market wakes up.
Memecoin launches. Liquidation cascades. The exact moments your agent needs precision. Shared endpoints start skipping slots. Tail latency stretches. Your p99 tells the real story. Meanwhile, a colocated bare-metal node keeps processing at ~40ms.
Dysnix ran a benchmark on 2,078,707 matched transactions comparing Jito ShredStream with Yellowstone gRPC.
.jpg)
Those numbers look small until you translate them into slots. Thirty-two milliseconds is the difference between landing in the same slot or slipping into the next one. In MEV terms, that’s the line between capturing value and paying for a failed bundle.
Engineers like to draw boxes and arrows and call it an “architecture.” On Solana, that diagram hides a simpler truth: your agent is a pipeline. Five layers, each doing one job. Break any one of them, and the whole thing slows down or lies to you.

Worse, the errors compound. Bad data in means bad decisions out. A slow submission path turns correct decisions into missed trades.
Your agent reads the state, then acts. If the read is stale or delayed, the action is wrong by definition.
Most teams reach for getAccountInfo over JSON-RPC and call it a day. It’s synchronous, rate-limited, and slow.
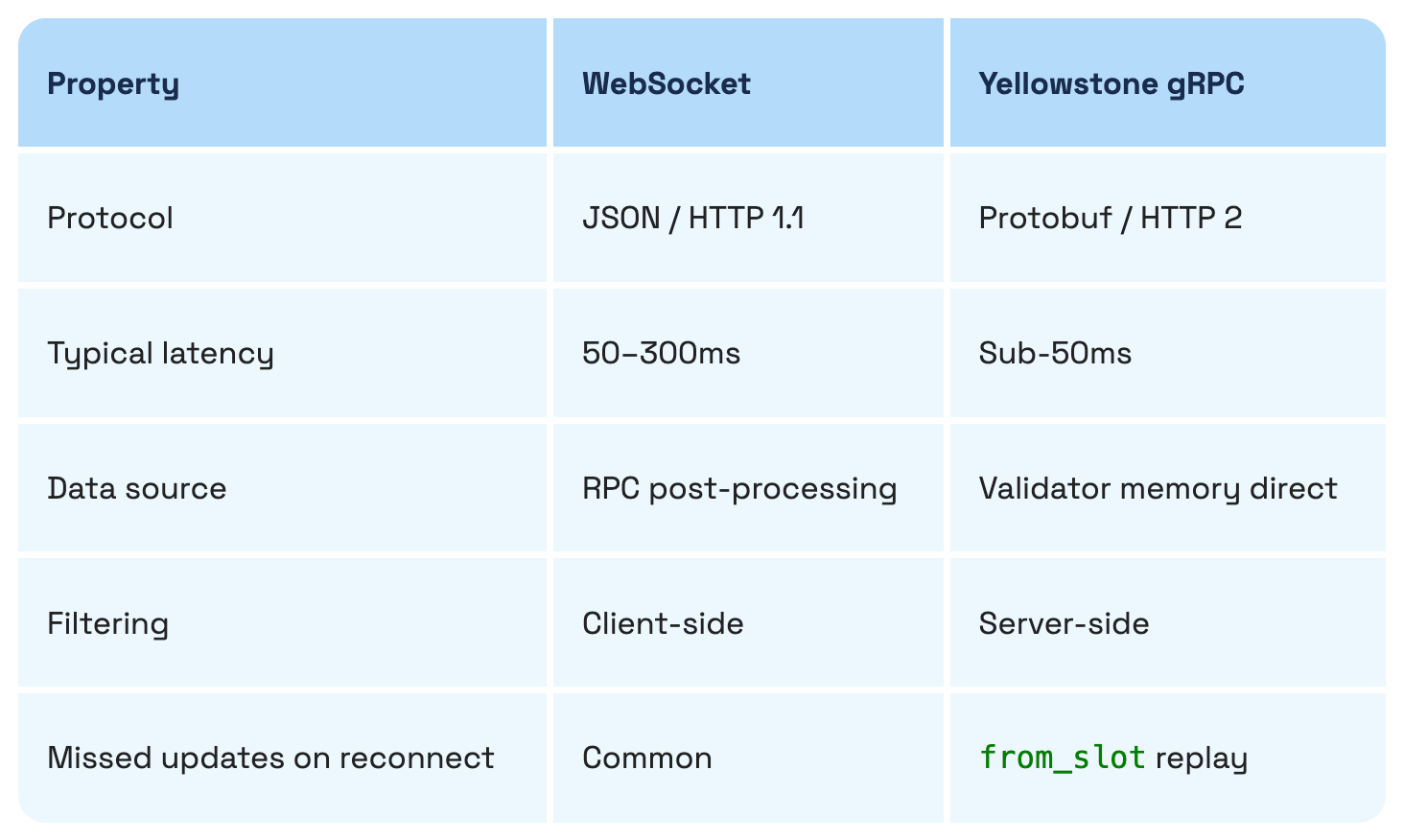
Poll every 100ms, and you still trail anything using a push model. You’re asking the network what happened instead of being told when it happens.
And there are two must-haves for that.
Use Yellowstone gRPC
Yellowstone gRPC (Dragon’s Mouth) fixes that by skipping the polite layer. You stream account updates, transactions, and slot changes straight out of validator memory, before JSON serialization and RPC overhead.
Two practical consequences:
Try ShredStream
Jito ShredStream hands you raw transaction shreds from the slot leader before the block finishes propagating. If you’re building copy-trading or chasing MEV, this is as early as Solana lets you see.
Data layer checklist
from_slot replay configured for reconnection recoveryYour RPC node isn’t plumbing. It’s the nervous system. Every read, every write, every subscription goes through it. If it hesitates, your agent hesitates. If it drops signals, your agent acts on an incomplete state.
Public endpoints look convenient until the network gets busy. api.mainnet-beta.solana.com is shared, rate-limited, and often far from the current leaders. When congestion hits, it degrades first. You see higher tail latency, dropped requests, and transactions that never land. From the outside, it looks like “the strategy failed.” In practice, the pipe failed.
Why shared is no longer an option for HFT
| Factor | Shared RPC SaaS | Dedicated bare-metal |
|---|---|---|
| Time to production | Minutes | Days |
| Latency ceiling | ~4ms (co-located) | Sub-1ms (same DC as validator) |
| Rate limits | Shared pool | None on dedicated |
| Noisy neighbor risk | Yes | No |
| Jito / gRPC support | Included | Included |
| Best for | Early-stage agents, DeFi automation | HFT, copy-trading, MEV |
Not every team needs dedicated bare-metal on day one. RPC Fast's Start SaaS tier is free, requires no card, and includes Beam for transaction delivery — enough to prototype and measure what your agent actually needs before you commit to more.
Start on the free tier to validate your call pattern with real numbers before scaling up.
A shared cloud VM has a different problem: you’ll never be alone sending your TXs. CPU and memory contention introduce latency spikes you don’t control. Solana’s throughput turns those spikes into missed slots at the worst time.
For latency-sensitive strategies, a dedicated path isn’t a luxury. It’s table stakes. Match the node to your call pattern instead of overbuilding:
getAccountInfo, simulateTransaction, getLatestBlockhashgetProgramAccounts, getTokenAccountsByOwnerRPC Fast's dedicated node tiers meet these patterns and ship Jito ShredStream and Yellowstone gRPC across all tiers. The point is removing shared bottlenecks, so your agent’s behavior reflects your logic, not someone else’s workload.
RPC Layer Checklist
Your agent did the hard part and made the right decision. Now it has ~400ms to prove it. Miss the current slot, and the same decision turns into a worse trade.
Transactions travel to the slot leader through RPC or relays, sit in a queue, and get included if two things hold: a fresh blockhash and enough priority. Leaders rotate every four slots, about 1.6 seconds. So, landing technically means to get into that time period with all conditions met.
If you care about order and atomicity for the highest chances of landing, use Jito bundles.
Jito's block engine accepts up to five transactions as a single bundle with a SOL tip. With ~92% of the stake on Jito validators, this path reaches the current leader more often than standard gossip does. For arbitrage, put buy and sell in one bundle. It executes all or nothing. No partial fills. No getting sandwiched between legs.

The catch is pricing the tip.
Treat tip size as a function of slot demand, not a constant. Add a second path—bloXroute.
bloXroute's BDN bypasses gossip with relay nodes and adds geographic spread. It covers cases where the leader sits in regions where your primary path has weaker connectivity. In October 2025, bloXroute added leader-aware routing, scoring current and upcoming leaders, and adjusting submission paths in real time.
The pragmatic setup is simple:
Cost stays marginal. Inclusion rate moves. Over time, that shows up in fills, not theories.
Execution layer checklist
Fast data and a clean submission path don’t help if the node disappears when the market rises. Five minutes of downtime in a liquidation cascade costs more than a month of infrastructure.
Start with the baseline: bare metal.
Shared VMs introduce jitter you don’t control. CPU steals, memory contention, noisy NICs. On Solana, that shows up as slot lag right when you need determinism.
Typical MEV setups converge on the same hardware:
Location matters as much as silicon.
High-stake validators cluster on the US East Coast (Ashburn, NY Metro) and Western Europe (Frankfurt, Amsterdam). Put your bot and RPC in the same facility as those validators, and you remove geographic hops between read, submit, and include.
Based on RPC Fast's internal benchmarks, co-location reduces latency by 5 to 10 times compared to a remote cloud configuration.
More on collocation strategy. Get rest from reading 🙂
After provisioning, tune the OS for throughput:
sysctl for TCP buffers sized to sustained high PPSirqbalance aligned with NIC queuesThese steps flatten p99 during spikes instead of letting tails drift.
Operate it like a trading system, not a web app. Things you have to monitor constantly:
If the node stays up and stays close to the tip, your strategy has a chance to behave as designed. If not, everything upstream is academic.
Network layer checklist
Case studies beat theory. Three setups, three different call patterns, three different outcomes.
A Rust agent sat in the same Frankfurt DC as its RPC node. Best-case landing hit ~15ms. In practice, it matched KOL wallets in the same slot or slipped by +1 slot. Under a 100,000-call stress run, the node held sub‑1ms responses with zero rate limiting.
The takeaway is proximity plus a dedicated path, not language choice.
Dysnix matched 2,078,707 transactions across both feeds. ShredStream arrived first in 64.5% of cases, with a 32.8ms average lead and peaks at 1,323ms. If your edge lives inside a slot, earlier data wins. Yellowstone alone is late for sub-slot arbitrage.
A yield agent hitting getAccountInfo and simulateTransaction on Kamino and Drift ran clean on a Light dedicated node. No getProgramAccounts, no wide scans. Infra cost stayed below the point where a heavier node pays back.
The pattern is boring and useful:
| Provider | Best for | ShredStream | gRPC | Dedicated | Latency |
|---|---|---|---|---|---|
| RPC Fast | AI trading, MEV, HFT | Default on the dedicated | Yellowstone | Bare-metal | Sub-4ms dedicated |
| Helius | Data-heavy, DeFi tooling | Available | Yes | Yes | Low, Solana-native |
| Triton One | MEV, market making | Available | Yellowstone advanced | Yes | ~100ms shared |
| QuickNode | Multi-chain, enterprise | Add-on | Yes | Yes | Good, global |
| GetBlock | EU/APAC dedicated value | Available | Yellowstone included | Yes | Fastest in the EU benchmark |
Most teams try to scale the strategy first. That’s backward. On Solana, the stack decides whether the strategy survives contact with the network. The agent layer is no longer the bottleneck. Frameworks hold up. Playbooks exist. The split between profitable bots and loss-making ones shows up lower in the stack.
Start where the errors originate: data.
Then fix the path to the leader:
Small wins stack. Trim ~30ms from data freshness, ~20ms from submission, ~10ms from colocation, and you stop missing slots your competitors capture.
If you’re unsure how your call pattern maps to a node tier, get a second set of eyes. RPC Fast & Dysnix run a free 1-hour infrastructure briefing focused on your architecture and workload.

Build faster with private RPC by Dysnix
Dedicated endpoints, gRPC, and raw streams for trading, AI agents, and dApps.
Test for free











.jpg)





